深入理解RocketMq普通消息和顺序消息使用,原理,优化




最近一直再做一些系统上的压测,并对一些问题做了优化,从这些里面收获了一些很多好的优化经验,后续的文章都会以这方面为主。
1. 背景
这次打压的过程中收获比较的大的是,对RocketMq的一些优化。最开始我们公司使用的是RabbitMq,再一些流量高峰的场景下,发现队列堆积比较严重,导致RabbitMq挂了。为了应对这个场景,最终我们引入了阿里云的RocketMq,RocketMq可以处理可以处理很多消息堆积,并且服务的稳定不挂也可以由阿里云保证。引入了RocketMq了之后,的确解决了队列堆积导致消息队列宕机的问题。
本来以为使用了RocketMq之后,可以万事无忧,但是其实在打压过程中发现了不少问题,这里先提几个问题,大家带着这几个问题在文中去寻找答案:
- 在RocketMq中,如果消息队列发生堆积,consumer会发生什么样的影响?
- 在RocketMq中,普通消息和顺序消息有没有什么办法提升消息消费速度?
- 消息失败重试次数怎么设置较为合理?顺序消息和普通消息有不同吗?
2. 普通消息 VS 顺序消息
在RocketMq中提供了多种消息类型让我们进行配置:
- 普通消息:没有特殊功能的消息。
- 分区顺序消息:以分区纬度保持顺序进行消费的消息。
- 全局顺序消息:全局顺序消息可以看作是只分一个区,始终再同一个分区上进行消费。
- 定时/延时消息:消息可以延迟一段特定时间进行消费。
- 事务消息:二阶段事务消息,先进行prepare投递消息,此时不能进行消息消费,当二阶段发出commit或者rollback的时候才会进行消息的消费或者回滚。
虽然配置种类比较繁多,但是使用得还是普通消息和分区顺序消息。后续主要讲得也是这两种消息。
2.1 发送消息
2.1.1 普通消息
普通消息的发送的代码比较简单,如下所示:
1
2
3
4
5
6
7
8
9
10
11 public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("test_group_producer");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
Message msg =
new Message("Test_Topic", "test_tag", ("Hello World").getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
producer.shutdown();
}
其内部核心代码为:
1 | private SendResult sendDefaultImpl(Message msg, final CommunicationMode communicationMode, final SendCallback sendCallback, final long timeout |
主要流程如下:
- Step 1: 根据Topic 获取TopicPublishInfo,TopicPublishInfo中有我们的Topic发布消息的信息(),这个数据先从本地获取如果本地没有,则从NameServer去拉取,并且定时每隔20s会去获取TopicPublishInfo。
- Step 2: 获取总共执行次数(用于重试),如果发送方式是同步,那么总共次数会有3次,其他情况只会有1次。
- Step 3: 从MessageQueue中选取一个进行发送,MessageQueue的概念可以等同于Kafka的partion分区,看作发送消息的最小粒度。这个选择有两种方式:
- 根据发送延迟进行选择,如果上一次发送的Broker是可用的,则从当前Broker选择遍历循环选择一个,如果不可用那么需要选择一个延迟最低的Broker从当前Broker上选择MessageQueue。
- 通过轮训的方式进行选择MessageQueue。
- Step 4: 将Message发送至选择出来的MessageQueue上的Broker。
- Step 5: 更新Broker的延迟。
- Step 6: 根据不同的发送方式来处理结果:
- Async: 异步发送,通过callBack关心结果,所以这里不进行处理。
- OneWay: 顾名思义,就是单向发送,只需要发给broker,不需要关心结果,这里连callback都不需要。
- Sync: 同步发送,需要关心结果,根据结果判断是否需要进行重试,然后回到Step3。
可以看见Rocketmq发送普通消息的流程比较清晰简单,下面来看看顺序消息。
2.1.2 顺序消息
顺序消息分为分区顺序消息和全局顺序消息,全局顺序消息比较容易理解,也就是哪条消息先进入,哪条消息就会先被消费,符合我们的FIFO,很多时候全局消息的实现代价很大,所以就出现了分区顺序消息。分区顺序消息的概念可以如下图所示: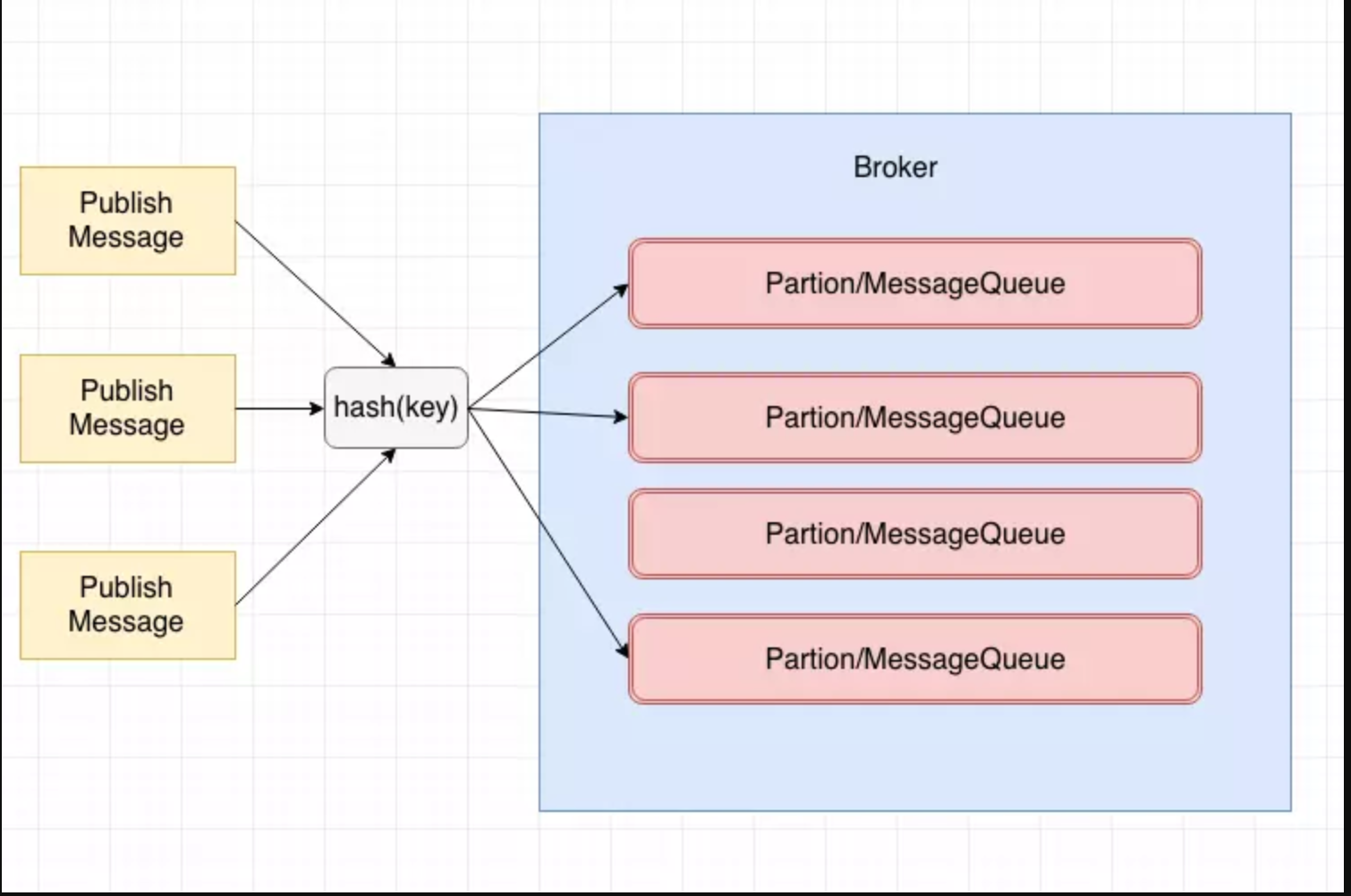
我们通过对消息的key,进行hash,相同hash的消息会被分配到同一个分区里面,当然如果要做全局顺序消息,我们的分区只需要一个即可,所以全局顺序消息的代价是比较大的。
对RocketMq熟悉的小伙伴会发现,它其实并没有提供顺序消息发送相关的API,但是在阿里云的RocketMq版本提供了顺序消息的API,原理比较简单,其实也是对现有API的一个封装:
1 | SendResult sendResultRMQ = this.defaultMQProducer.send(msgRMQ, new MessageQueueSelector() { |
可以看见顺序消息将MessageQueue的选择交由我们发送方去做,所以我们直接利用我们shardingKey的hashCode进行发送分区。
3.1 消费消息
3.1.1 普通消息
普通消息使用比较简单,如下面代码所示:
1 | public static void main(String[] args) throws InterruptedException, MQClientException { |
- Step1:首先新建一个DefaultMQPushConsumer,并注册对应的Topic和NameServer的信息。
- Step2: 注册消息监听器,再RocketMq中有两种消息监听器,一个是MessageListenerConcurrently,用于我们普通消息并发消费,还有一个是MessageListenerOrderly,用于我们顺序消息。这里我们使用的MessageListenerConcurrently。
- Step3: 设置ConsumeThread大小,用于控制我们的线程池去消费他。
- Step4: 启动Consumer。
启动Consumer之后,我们就开始真正的从Broker去进行消费了,但是我们如何从Broker去消费的呢?首先在我们的第一步里面我们订阅了一个Topic,我们就会定时去刷新Topic的相关信息比如MessageQueue的变更,然后将对应的MessageQueue分配给当前Consumer:
1 | // 这个数据 是10s更新一次 从内存中获取 |
这里首先向Broker拿到当前消费所有的ConsumerId默认是对应机器的Ip+实例名字,Broker中的ConsumerId信息是Consumer通过心跳定时进行上报得来的,然后根据消费分配策略将消息分配给Consumer,这里默认是平均分配,将我们分配到的消息队列,记录在
processQueueTable中,如果出现了新增,那么我们需要创建一个PullRequst代表这拉取消息的请求,异步去处理:
1 | List<PullRequest> pullRequestList = new ArrayList<PullRequest>(); |
在PullService中会不断的从PullRequestQueue拿取数据,然后进行拉取数据。
1 | while (!this.isStopped()) { |
拉取数据之后,这里会给PullCallBack进行响应:
1 | PullCallback pullCallback = new PullCallback() { |
如果这里成功拉取到消息的话,我们首先将拉取的消息存入到我们的ProcessQueue中,ProcessQueue用于我们消费者处理的状态以及待处理的消息,然后提交到我们的Consumer线程池中进行真正的业务逻辑消费,然后再提交一个PullRequest用于我们下次消费。
大家看到这里有没有发现这个模式和我们的netty中的单线程accpet,多个线程来处理业务逻辑很相似,其原理都是一样,由一个线程不断的去拉取,然后由我们业务上定义的线程池进行处理。如下图所示:

我们发现我们拉取消息其实是一个循环的过程,这里就来到了第一个问题,如果消息队列消费的速度跟不上消息发送的速度,那么就会出现消息堆积,很多同学根据过程来看可能会以为,我们的拉取消息一直在进行,由于我们的消费速度比较慢,会有很多message以队列的形式存在于我们的内存中,那么会导致我们的JVM出现OOM也就是内存溢出。
那么到底会不会出现OOM呢?其实是不会的,RocketMq对安全性方面做得很好,有下面两段代码:
1 | if (cachedMessageCount > this.defaultMQPushConsumer.getPullThresholdForQueue()) { |
首先是会判断当前内存缓存的Message数量是否大于限制的值默认是1000,如果大于则延迟一段时间再次提交pullRequest。
然后判断当前内存缓存的Size大小是否大于了某个值,默认是100M,如果大于也会延迟一段时间再次提交pullRequest。
所以在我们consumer上如果出现消息堆积,基本也没有什么影响。
那我们想想第二个问题应该怎么解决呢?再普通消息的场景下,如何提升消费速度?
- 首先肯定是需要提升我们本身的处理速度,处理速度提升,消费速度自然就会提升。
- 其次是要设置一个合理大小的consumer线程池,太小的话机器的资源得不到充分利用,太大的话线程的上下文切换可能会很快,一般来说根据消费者的业务来判断,如果是cpu密集型线程设置cpu大小就好,如果是io密集型设置两倍cpu大小。
- 还有个就是MessageQueue,细心的同学肯定在上面看见我们消费者消费消息之前,会被分配MessageQueue来进行获取消费,所以自然而然就会想到,如果多分配一点MessageQueue数量是不是就会加快我们的消费速度,其实MessageQueue对于我们的普通消息消费提升帮助是很小的,因为所有的消费请求会被提交到线程池里面去消费,MessageQueue再多也无济于事,除非当我们的Consumer机器很多的时候,MessageQueue数量小于Consumer机器的时候,这个时候增加MessageQueue才会有提升效果,正所谓让我们的机器雨露均沾嘛。
3.1.1.1普通消息-消费结果处理
在rocketmq中对消息的消费结果处理也比较重要,这里还是先提三个问题:
- 我们的普通消息是怎么处理结果的呢?
- 如果消费失败会怎么办呢?
- 在普通消息消费的时候,是并发处理,如果出现offset靠后的消息先被消费完,但是我们的offset靠前的还没有被消费完,这个时候出现了宕机,我们的offset靠前的这部分数据是否会丢失呢?也就是下次消费的时候是否会从offset靠后的没有被消费的开始消费呢?如果不是的话,rocketmq是怎么做到的呢?
首先我们来看第一个问题,怎么处理消费结果,在processResult中有如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56public void processConsumeResult(
final ConsumeConcurrentlyStatus status,
final ConsumeConcurrentlyContext context,
final ConsumeRequest consumeRequest
) {
int ackIndex = context.getAckIndex();
switch (status) {
case CONSUME_SUCCESS:
int ok = ackIndex + 1;
int failed = consumeRequest.getMsgs().size() - ok;
this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok);
this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed);
break;
case RECONSUME_LATER:
ackIndex = -1;
this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(),
consumeRequest.getMsgs().size());
break;
default:
break;
}
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {
MessageExt msg = consumeRequest.getMsgs().get(i);
log.warn("BROADCASTING, the message consume failed, drop it, {}", msg.toString());
}
break;
case CLUSTERING:
List<MessageExt> msgBackFailed = new ArrayList<MessageExt>(consumeRequest.getMsgs().size());
for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {
MessageExt msg = consumeRequest.getMsgs().get(i);
boolean result = this.sendMessageBack(msg, context);
if (!result) {
msg.setReconsumeTimes(msg.getReconsumeTimes() + 1);
msgBackFailed.add(msg);
}
}
if (!msgBackFailed.isEmpty()) {
consumeRequest.getMsgs().removeAll(msgBackFailed);
this.submitConsumeRequestLater(msgBackFailed, consumeRequest.getProcessQueue(), consumeRequest.getMessageQueue());
}
break;
default:
break;
}
long offset = consumeRequest.getProcessQueue().removeMessage(consumeRequest.getMsgs());
if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {
this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset(consumeRequest.getMessageQueue(), offset, true);
}
} - Step 1: 首先获取ackIndex,即确认成功的数量,默认是int的最大数,代表着全部成功。
- Step 2: 获取 ConsumeConcurrentlyStatus,根据不同的状态进行处理,ConsumeConcurrentlyStatus有两个:
- CONSUME_SUCCESS: 代表着消费成功,记录成功的TPS和失败的TPS。
- RECONSUME_LATER: 代表着需要重新消费,一般是失败才会返回这个状态,记录失败的TPS。
- Step 3: 然后根据消息类型,进行不同的逻辑重试,消息消费类型有两种:
- BROADCASTING: 广播消费,广播消费不会进行重试,这里会直接打一个warn日志然后丢弃。
- CLUSTERING:集群消费,这里会首先将失败的消息发送回当前的topic,如果发送失败,这里会继续进行本地消费重试。如果在Broker中发现这个消息重试次数已经达到上限,就会将这个消息发送至RetryTopic,然后由RetryTopic发送至死信队列。
- Step 4: 获取message的offset,更新当前消费进度
在上面的第四步中,如果不深入进去看内部逻辑,这里会误以为,他会将当前消息的offset给更新到最新的消费进度,那问题三中说的中间的offset是有可能被丢失的,但实际上是不会发生的,具体的逻辑保证在removeMessage中:
1 | public long removeMessage(final List<MessageExt> msgs) { |
在removeMessage中通过msgTreeMap去做了一个保证,msgTreeMap是一个TreeMap,根据offset升序排序,如果treeMap中有值的话,他返回的offset就会是当前msgTreeMap中的firstKey,而不是当前的offset,从而就解决了问题三。
上面的过程总结为下图所示: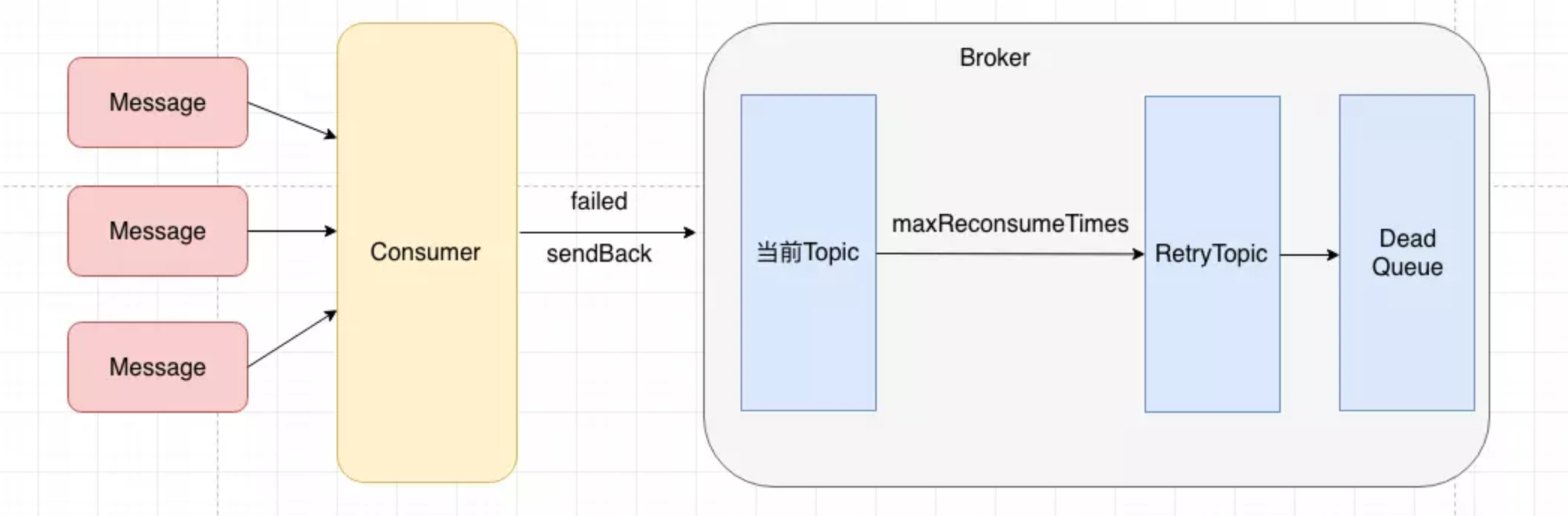
3.1.2 顺序消息
顺序消息的消费前面过程和普通消息基本一样,这里我们需要关注的是将消息丢给我们消费线程池之后的逻辑:
1 | final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue); |
可以发现这里比普通消息多了一个步骤,那就是加锁,这里会获取到以messageQueue为纬度去加锁,然后去我们的processQueue中获取到我们的Message, 这里也是用的我们的msgTreeMap, 获取的最小offset的Message。
所以我们之前的线程池提高并发速度的策略在这里没有用了,那么应该怎么办呢?既然我们加锁是以messageQueue为纬度,那么增加MessageQueue就好了,所以这里的提升消费速度刚好和普通消息相反,再普通消息中提升Messagequeue可能效果并没有那么大,但是在顺序消息的消费中提升就很大了。
我们在压测的时候,发现顺序消息消费很慢,消息堆积很严重,经过调试发现阿里云上的rocketmq默认读写队列为16,我们consumer机器有10台,每个consumer线程池大小为10,理论并发应该有100,但是由于顺序消息的原因导致实际并发只有16,最后找阿里的技术人员将读写队列扩至100,这样充分利用我们的资源,极大的增加了顺序消息消费的速度,消息基本不会再堆积。
3.1.2.1 顺序消息-消费结果处理
顺序消息的结果处理和普通消息的处理流程,稍有不同,代码如下:
1 | public boolean processConsumeResult( |
- Step 1: 判断当前offset是否是自动提交更新,一般autoCommit不需要设置,默认是自动提交,除非有特别的需求才会做这样一个设置。
- Step 2: 如果是自动提交,需要判断状态:
- SUCCESS: 如果是成功状态则获取当前需要提交的offset,然后记录到OK的TPS中
- SUSPEND_CURRENT_QUEUE_A_MOMENT:注意在普通消息中如果失败会返回RECONSUME_LATER,有什么不同呢?再这个状态下面,并不会向当前topic再次发送,而是会在本地线程池再次提交一个ConsumeRequest,延迟重试,这里默认时间是1s。如果大于了最大重试次数这里会将数据发送至RetryTopic。
- Step 3: 如果不是自动提交的话,和步骤2类似,但是不会获取提交的offset。
- Step 4: 更新offset。
这里回到我们的第三个问题,如何设置消息消费的重试次数呢?由于我们直接使用的阿里云的mq,所以我们又包装了一层,方便接入。再接入层中我们最开始统一配置了最大重试2000次,这里设置2000次的原因主要是想让我们的消息队列尽量无限重试,因为我们默认消息基本最终会成功,但是为了以防万一,所以这里设置了一个较大的数值2000次。设置2000次对于我们的普通消息,基本没什么影响,因为他会重新投递至broker,但是我们的顺序消息是不行的,如果顺序消息设置重试2000次,当遇到了这种不可能成功的消息的时候就会导致消息一直在本地进行重试,并且由于对队列加锁了,所以当前MessageQueue将会一直被阻塞,导致后续消息不会被消费,如果设置2000次那么至少会阻塞半个小时以上。所以这里应该将顺序消息设置一个较小的值,目前我们设置为16。
4. 最后
之前没怎么看过Rocketmq的源码,经过这次打压,从Rocketmq中学习到了很多精妙优秀的设计,将一些经验提炼成了文中的一些问题,希望大家能仔细阅读,找到答案。

 OAuth vs SAML vs OpenID
OAuth vs SAML vs OpenID




